论文方向探索-02
一、创新思路
刨根问底法
此种方法最为直接,即知其然也要知其所以然。如果你提的小改进使得结果变好了,那结果变好的原因是什么?什么条件下结果能变好、什么条件下不能?提出的改进是否对领域内同类方法是通用的?这一系列问题均可以进行进一步的实验和论证。你看,这样你的文章不就丰富了嘛。这也是对领域很重要的贡献。
移情别恋法
不在主流任务/会议期刊/数据集上做,而是换一个任务/数据集/应用,因此投到相应的会议或期刊上。这么一来,相当于你是做应用、而不是做算法的,只要写的好,就很有可能被接受。当然,前提是该领域确实存在此问题。无中生有是不可取的,反而会弄巧成拙。写作时一定要结合应用背景来写,突出对领域的贡献。
声东击西法
虽然实际上你就做了一点点提升和小创新,但你千万不能这么老实地说呀。而是说,你对这个A + B的两个模块背后所代表的两大思想进行了深入的分析,然后各种画图、做实验、提供结果,说明他们各自的局限,然后你再提自己的改进。这样的好处是你的视角就不是简单地发一篇paper,而是站在整个领域方法论的角度来说你的担忧。这种东西大家往往比较喜欢看、而且往往看题目和摘要就觉得非常厉害了。这类文章如果分析的好,其价值便不再是所提出的某个改进点,而是对领域全面而深刻的分析。
移花接木法
不说你提点,甚至你不提点都是可以的。怎么做呢?很简单,你就针对你做的改进点,再发散一下,设计更大量的实验来对所有方法进行验证。所以这篇paper通篇没有提出任何方法,全是实验。然后你来一通分析(分析结果也大多是大家知道的东西)。但这不重要啊,重要的是你做了实验验证了这些结论。典型代表:Google家的各种财大气粗做几千个实验得出大家都知道的结论的paper,比如ICLR’22这篇:Exploring the Limits of Large Scale Pre-training
二、期刊论文改进的特点总结
改进共性特点
注意力机制
- 2-4个不等
创新点 - 基于
YOLOv5的居多 - 创新点并不是特别复杂
CNN和Transformer(ViT)结合的不少- 使用swin、bot等transformer
- 改进基本上都是在YOLO框架上小改,backbone,neck,head,小幅改进
- 应用在私有数据集 或者 垂直领域数据集
- 增加检测层
- 添加注意力机制(CBAM、SE、SA等)
- 使用各种卷积模块(eg: Ghostbottleneck)
- 使用其他loss函数,比如diou giou siou
- 使用 ResNeSt、densenet、resnet等网络
- 使用重参数化网络(Repvgg等)
- 使用各种改进的金字塔池化,一般级别论文基本都是不同模块进行组合、级别高一点的期刊论文就需要自己改一些特有的结构,有自己的亮点
三、论文十问
Q1:论文试图解决什么问题?
RAFT-Stereo 提出了一种新的双目立体匹配框架,其未使用三维卷积,也未使用级联的方式进行特征提取,而是从Recurrent allpairs field transforms for optical flow 这篇论文中得到启发,使用GRU updates进行迭代从而寻找到匹配像素。该论文旨在解决 RAFT-Stereo 中 all-pairs correlations lack non-local geometry knowledge and have difficulties tackling local ambiguities in ill-posed regions 的问题。 |
Q2:这是否是一个新的问题?
Q3:这篇文章要验证一个什么科学假设?
证明其添加模块的有效性 |
Q4:有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
Q5:论文中提到的解决方案之关键是什么?
采用与GwcNet相同思路的组建相关性代价体 |
Q6:论文中的实验是如何设计的?
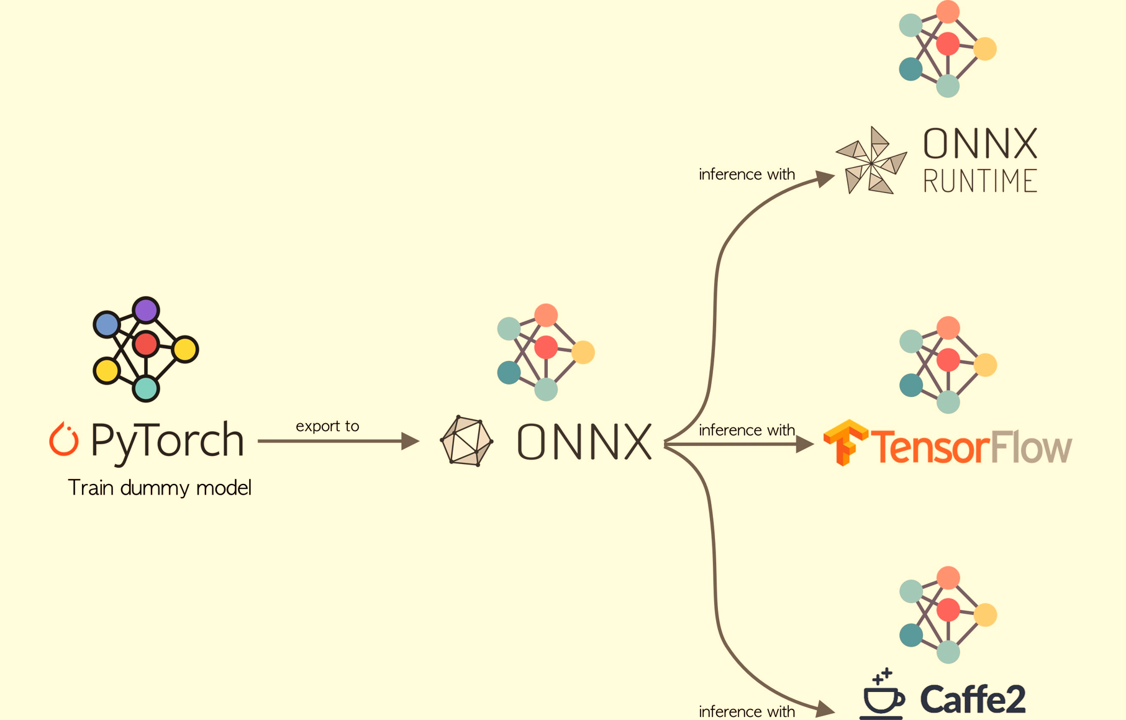
消融实验,证明三个模块的有效性: |
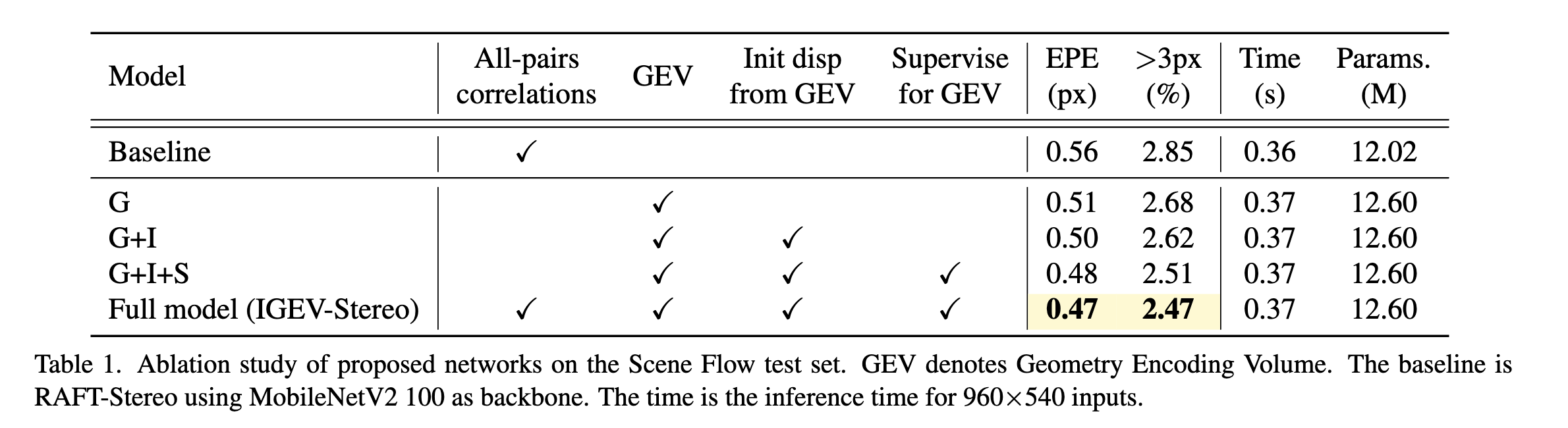
同其他网络的performance作对比: |
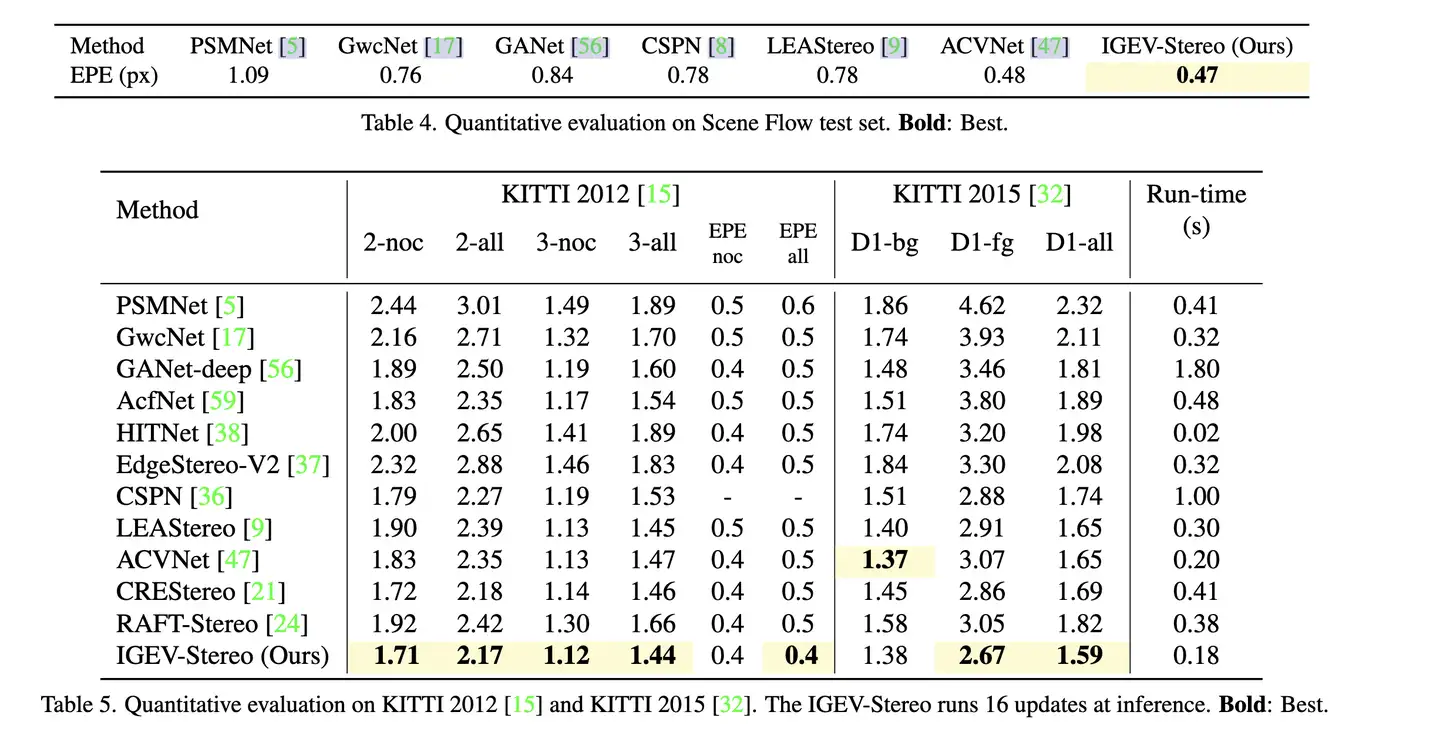
Q7:用于定量评估的数据集是什么?代码有没有开源?
secenflow kitti2015 Middlebury 等。 |
Q8:论文中的实验及结果有没有很好地支持需要验证的科学假设?
有,消融实验证明了添加模块的有效性。 |
Q9:这篇论文到底有什么贡献?

现有的先进的双目立体匹配方法,主要分为基于代价滤波的方法以及基于迭代优化的方法(以RAFT为代表)。前者可以在cost volume中编码足够的非局部几何和上下文信息,这对于具有挑战性的区域中的视差预测至关重要。后者可以避免进行3D代价聚合所需的高计算和内存成本,但是仅基于All-pairs Correlations的方法在病态区域的能力较弱。 |
Q10:下一步呢?有什么工作可以继续深入?
论文使用一个轻量级的3D CNN来过滤cost volume并获得GEV。然而,当处理显示出较大视差范围的高分辨率图像时,使用3D CNN来处理由此产生的大尺寸 cost volume仍然会导致较高的计算和内存成本。未来的工作包括设计一个更轻量级的正则化网络。此外,论文还将探索利用cascaded cost volumes,使本文的方法适用于高分辨率图像。 |
- 微信
- 支付宝