Backbone轻量化项目实践
前言
目前在一家自动驾驶公司做视觉感知算法实习生。近期主要工作是对某个项目网络模型(本次模型部分参考YOLOv8框架)进行Backbone方面的轻量化,期间涉及的一些知识点,在此Record一下。
如何从轻量化角度改进YOLOv8?
压缩YOLOv8模型
对于YOLOv8模型,我们可以采用模型压缩的方法来减小模型的大小。模型压缩包括模型量化、模型剪枝和模型蒸馏等技术。模型量化是将浮点模型转换为定点模型,可以减小模型大小。模型剪枝是指去除模型中冗余的权重和神经元,可以减少模型的参数量。模型蒸馏是通过在小模型中嵌入大模型的知识来提高小模型的精度。这些方法可以结合使用,以实现更好的效果。
改进YOLOv8的骨干网络
YOLOv8的骨干网络是Darknet53,虽然Darknet53有较好的性能,但在实际应用中,它的计算量较大。为了减小计算量,我们可以考虑使用轻量级网络来替代Darknet53,例如MobileNet、ShuffleNet等。这些网络具有更小的计算量和更少的参数量,可以提高模型的效率和精度。
优化YOLOv8的损失函数
YOLOv8的损失函数包括分类损失和定位损失。在实际应用中,我们可以根据具体的应用场景,对损失函数进行优化。例如,在一些应用场景中,对于目标的定位更为关键,我们可以考虑提高定位损失的权重,从而提高目标的定位精度。
四、增加YOLOv8的数据增强
数据增强是提高模型泛化能力的重要手段。对于YOLOv8模型,我们可以通过增加数据增强的方法来提高模型的泛化能力。例如,随机裁剪、随机旋转、随机缩放等数据增强方法,可以增加模型的数据多样性。
引入注意力机制
注意力机制是一种提高模型精度的有效手段。通过引入注意力机制,模型可以更加关注关键的目标区域,从而提高模型的精度。在YOLOv8模型中,我们可以引入注意力机制来增强模型对目标的关注程度。例如,SENet(Squeeze-and-Excitation Network)模型通过学习每个通道的权重来加强重要的特征通道,从而提高模型的准确率。
改进YOLOv8的后处理算法
后处理算法是目标检测算法中的重要环节。在YOLOv8模型中,后处理算法负责对模型输出的结果进行筛选和修正。在实际应用中,我们可以根据不同的应用场景对后处理算法进行优化。例如,采用非极大值抑制(NMS)算法来对重叠的目标进行筛选,同时引入一些修正策略,如像素点修正等方法,可以提高模型的准确率和鲁棒性。
结合其他技术进行优化
除了以上几种方法外,我们还可以结合其他的技术来优化YOLOv8模型。例如,我们可以采用超分辨率技术来提高输入图像的分辨率,从而提高模型的精度。此外,我们还可以采用GAN(Generative Adversarial Network)等技术来生成更多的数据样本,从而增加模型的数据多样性。
本次项目尝试使用一些特殊的模型方法来进行改进。
深度学习中常用的Backbone:
AlexNet:在2012年ImageNet挑战赛中首次引入的CNN,具有8层神经网络。VGG:由Simonyan和Zisserman于2014年提出的一种卷积神经网络,它采用小尺寸的3×3卷积核来替代传统的5×5或7×7卷积核。ResNet:由Microsoft Research Asia在2015年提出的一种卷积神经网络,通过引入残差连接解决了深度神经网络中的梯度消失问题。Inception系列网络:由Google在2014年提出的一种卷积神经网络,其特点是使用多个不同大小的卷积核来提取不同层次的特征。MobileNet:一种轻量级的卷积神经网络,可以在移动设备上快速运行,它使用深度可分离卷积来减少参数数量和计算复杂度。EfficientNet:由谷歌在2019年提出的一种卷积神经网络,它使用复合系数扩展方法来提高模型的效率和准确性。ResNeXt:由Facebook在2017年提出的一种卷积神经网络,通过并行连接多个小型卷积核来提高模型的准确性和效率。
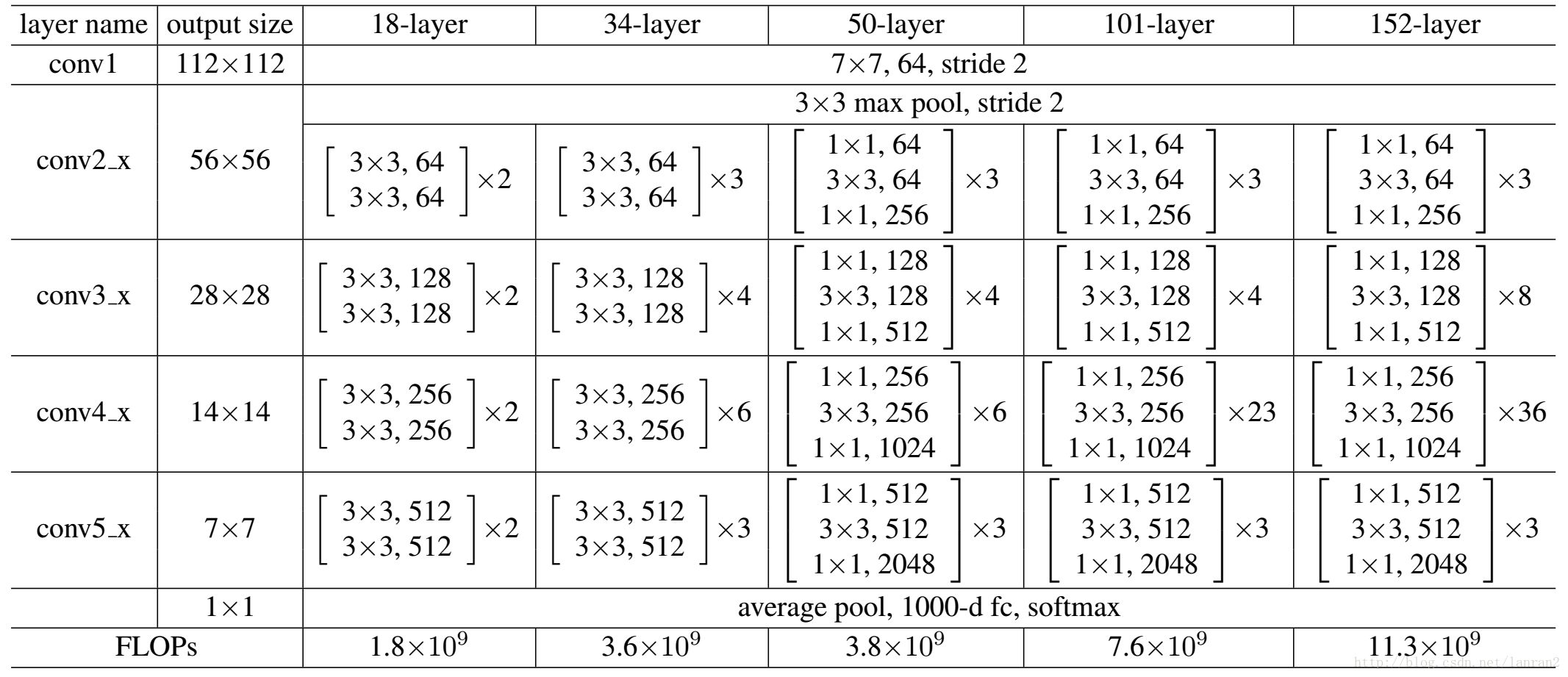
这里以resnet50模块代码实例进行网络层级分析:
# 基础网络:resnet50 |
部分特殊的网络结构:
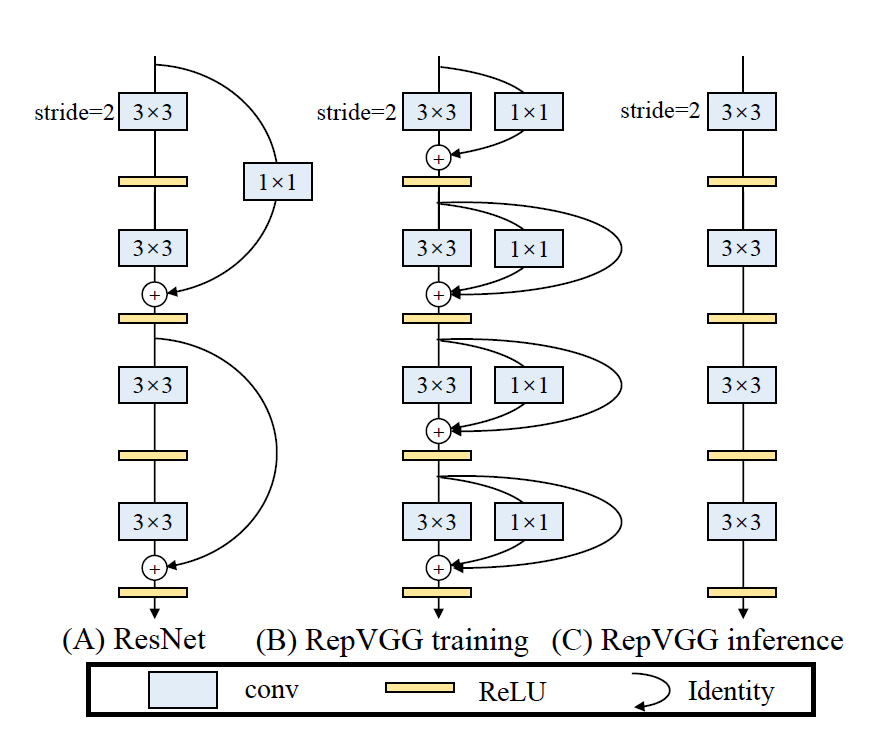
RepVGG
我们说的 VGG 式网络结构通常是指:
- 没有任何分支结构,即通常所说的
plain或feed-forward架构。 - 仅使用 3×3 类型的卷积。
- 仅使用
ReLU作为激活函数。
RepVGG 主体部分只有一种算子:3x3 卷积接 ReLU。在设计专用芯片时,给定芯片尺寸或造价,可以集成海量的 3x3 卷积-ReLU 计算单元来达到很高的效率,同时单路架构省内存的特性也可以帮我们少做存储单元。
在训练时,为每一个 3x3 卷积层添加平行的 1x1 卷积分支和恒等映射分支,构成一个 RepVGG Block。这种设计是借鉴 ResNet 的做法,区别在于 ResNet 是每隔两层或三层加一分支,RepVGG 模型是每层都加两个分支(训练阶段)。
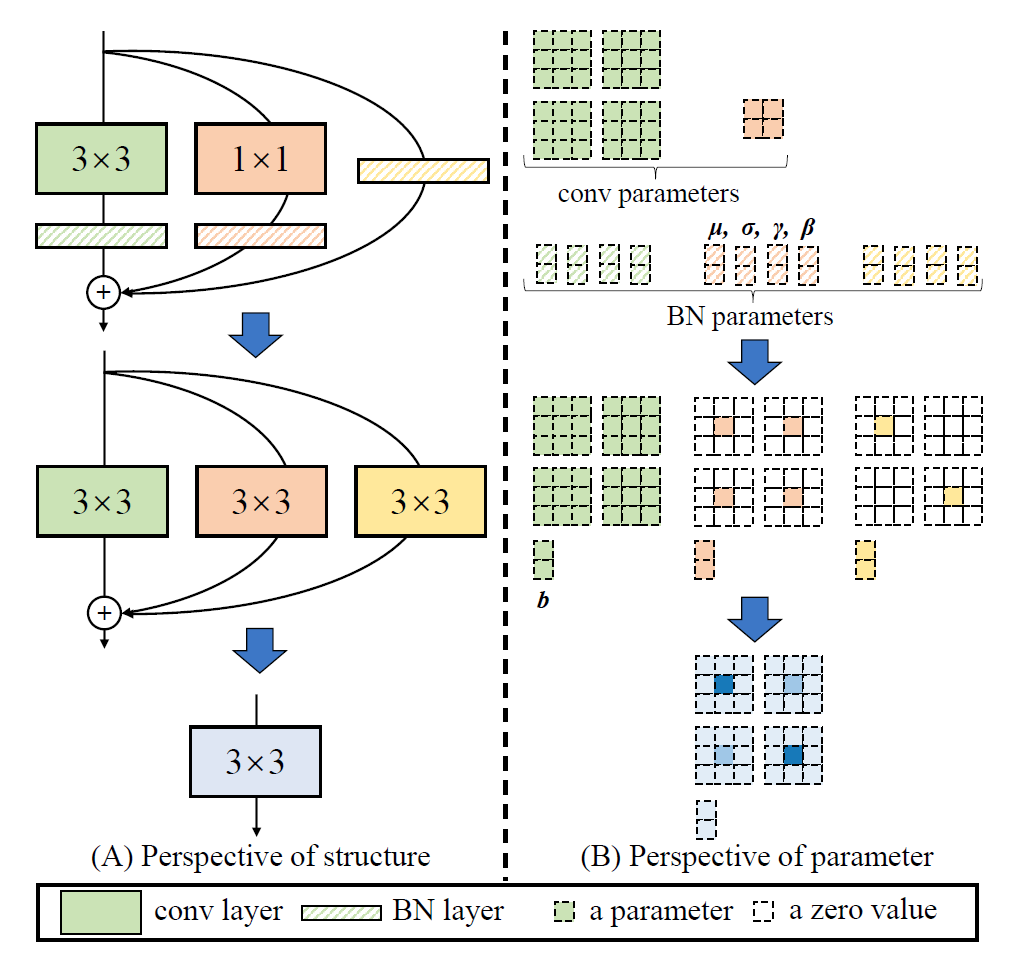
结构重参数化
卷积运算,可以看作是一串内积运算,等效于矩阵相乘,因此卷积满足交换、结合等定律。
训练时使用多分支卷积结构,推理时将多分支结构进行融合转换成单路 3×3 卷积层,由卷积的线性(具体说就是可加性)原理,每个 RepVGG Block 的三个分支可以合并为一个 3×3 卷积层(等价转换)。注意三个分支都有BN(batch normalization)层,其参数包括累积得到的均值及标准差和学得的缩放因子及bias。这并不会妨碍转换的可行性,因为推理时的卷积层和其后的BN层可以等价转换为一个带bias(偏置)的卷积层(也就是通常所谓的“吸BN”)。推理时,BN是一个线性的操作,也就是一个缩放 + 一个偏移,我们完全可以把这个线性操作叠加到前面的全连接层或者卷积层,只需要把全连接或者卷积层的权重乘以一个系数,偏置从 c 变为 ac+b 就可以了。
对三分支分别“吸BN”之后(注意恒等映射可以看成一个“卷积层”,其参数是一个2x2单位矩阵!),将得到的1x1卷积核用0给pad成3x3。最后,三分支得到的卷积核和bias分别相加即可。这样,每个RepVGG Block转换前后的输出完全相同,因而训练好的模型可以等价转换为只有3x3卷积的单路模型。
ACNet
概念结构重参数化(structural re-parameterization)指的是首先构造一系列结构(一般用于训练),并将其参数等价转换为另一组参数(一般用于推理),从而将这一系列结构等价转换为另一系列结构。
ACNet 的创新分为训练和推理阶段:
- 训练阶段:将现有网络中的每一个 3×3 卷积层换成 3×1 卷积 + 1×3 卷积 + 3×3 卷积共三个卷积层,并将三个卷积层的计算结果进行相加得到最终卷积层的输出。因为这个过程引入的 1×3 卷积和 3×1 卷积是非对称的,所以将其命名为
Asymmetric Convolution(AC)。论文中有实验证明(见论文Table 4)引入 1×3 这样的水平卷积核可以提升模型对图像上下翻转的鲁棒性,竖直方向的 3×1 卷积核同理。 - 推理阶段:主要是对三个卷积核进行融合,这部分在实现过程中就是使用融合后的卷积核参数来初始化现有的网络。
推理阶段的卷积融合操作是和 BN 层一起的,融合操作发生在 BN 之后,论文实验证明融合在 BN 之后效果更好些。
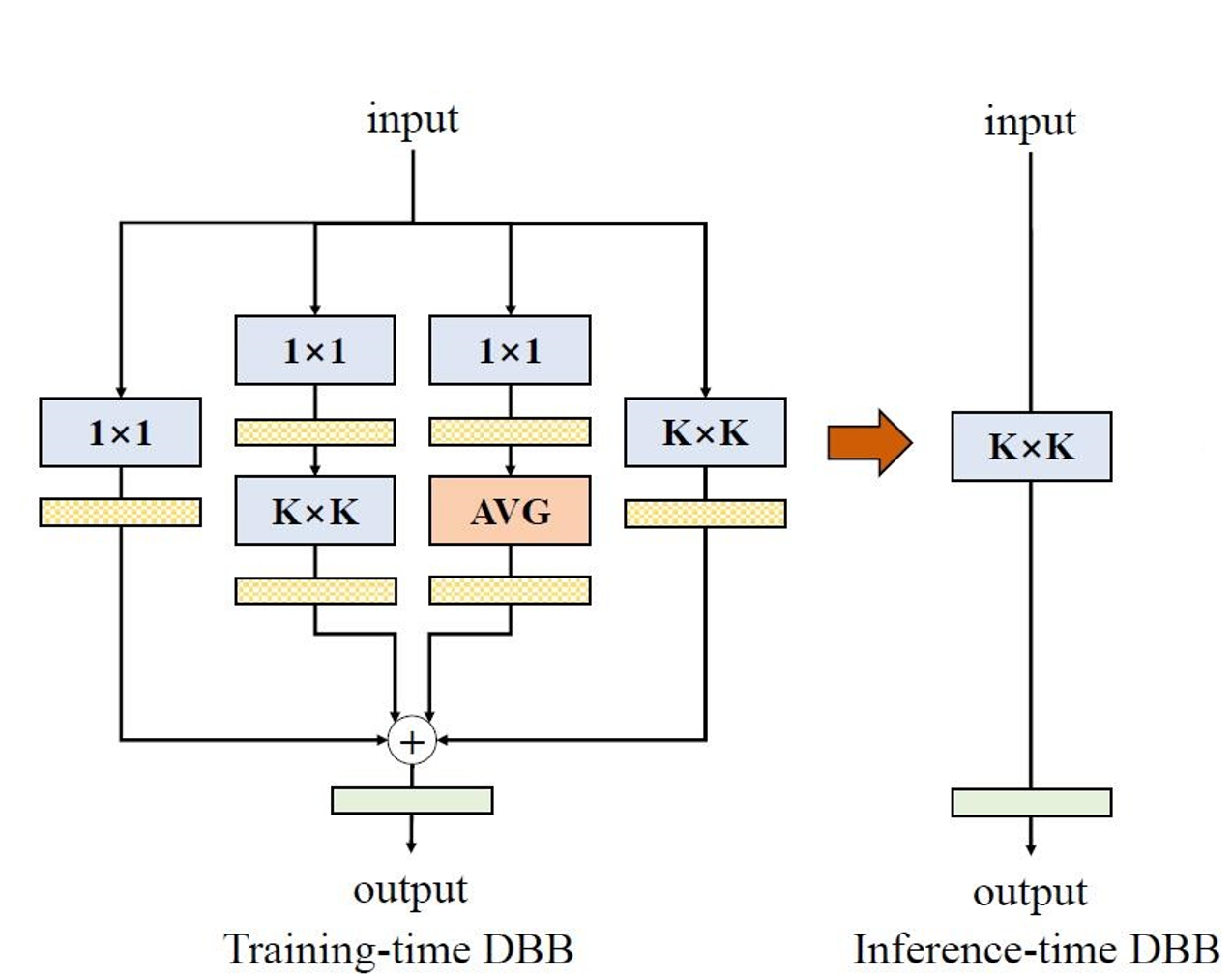
DBB-Net
DBB-Net是ACNet的续作(ACNet v2),同样是对训练时的模块在测试时做结构重参数化,以实现推理时无痛涨点的工作。DBB 模型并不依赖于特定的 backbone 结构,而是采用了一种多分支的设计思路,可以与各种常见的 backbone 结构进行结合。
DBB-Net借鉴Inception的多分支并行结构提出了DBB(Diverse Branch Block),在测试时多分支通过结构重参数化成单分支。
训练时的DBB由4个分支构成:
- 1x1卷积+BN
- 1x1卷积+BN+K×K卷积+BN
- 1x1卷积+BN+平均池化+BN
- K×K卷积+BN
四个分支的结果相加后,经由激活函数输出结果。
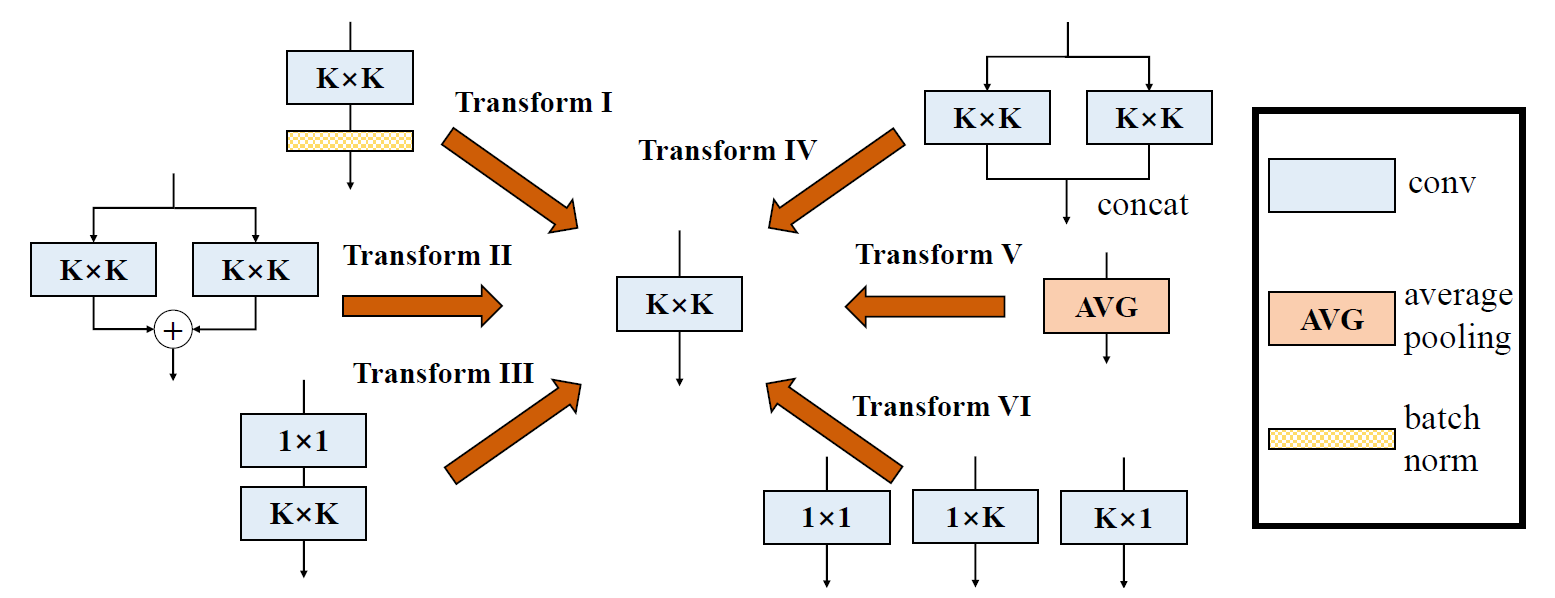
文章给出了6种DBB形态的转换方式:
DBB和RepVGG之间是什么关系?
RepVGG是一个普通架构,RepVGG风格的结构重参是为普通架构设计的。在非普通架构上,与单个 3x3 Conv相比,RepVGG 块没有显示出任何优势( RepVGG 论文中指出,它仅将 Res-50 提高了 0.03%)。DBB 是一个通用构建块(building block),可用于多种架构,取代常规的Conv。
如何修改YOLOv8的Backbone部分?
Backbone:YOLOv8使用的依旧是CSP的思想,不过YOLOv5中的C3模块被替换成了C2f模块,实现了进一步的轻量化。
针对C3模块,其主要是借助CSPNet提取分流的思想,同时结合残差结构的思想,设计了所谓的C3 Block,这里的CSP主分支梯度模块为BottleNeck模块,也就是所谓的残差模块。同时堆叠的个数由参数n来进行控制,也就是说不同规模的模型,n的值是有变化的。
这里的梯度流主分支,可以是任何之前你学习过的模块,比如,美团提出的YOLOv6中就是用来重参模块RepVGGBlock来替换BottleNeck Block来作为主要的梯度流分支,而百度提出的PP-YOLOE则是使用了RepResNet-Block来替换BottleNeck Block来作为主要的梯度流分支。而YOLOv7则是使用了ELAN Block来替换BottleNeck Block来作为主要的梯度流分支。
YOLOv8原框架修改方法:
- 修改
modules.py,增加待添加的模块,例如MobileNet、ShuffleNet等; - 在
tasks.py中注册模块; - 修改
yaml文件中对应的backbone等部分;
公司代码框架中采用了Encoder(编码器) 和Decoder(解码器) 以及Head(头任务) 的trick来套用各种网络模块。
编码器将网络分为了许多 *块 (block),此处的block不能理解为神经网络的一层 (layer)*。事实上,一个block为 神经网络的几个layer,整个网络为若干个block的堆叠。
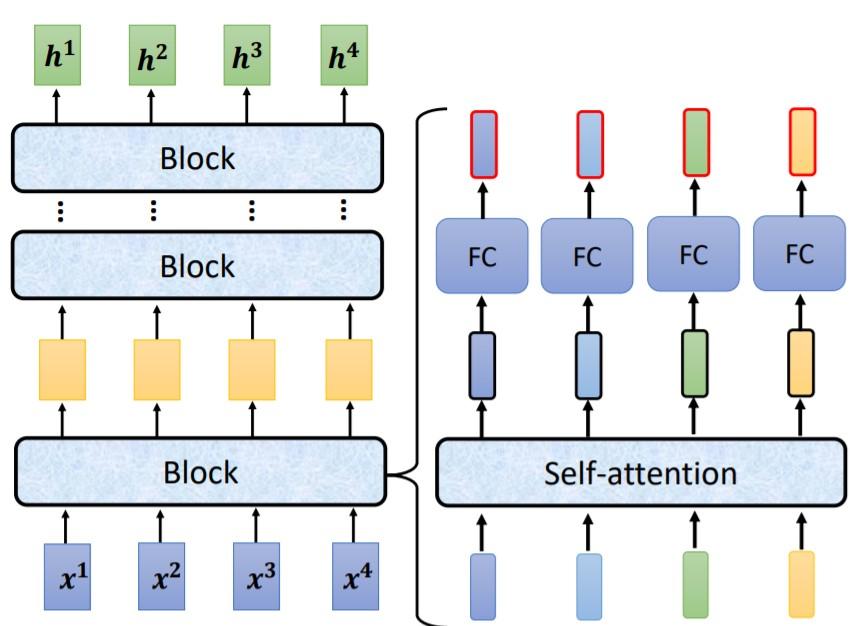
如上图所示是一个简化版的Transformer编码器,其中一个block的工作为:先将输入送入自注意力汇聚机制,然后将自注意力层的输出经过全连接 (FC) 层得到block的输出。
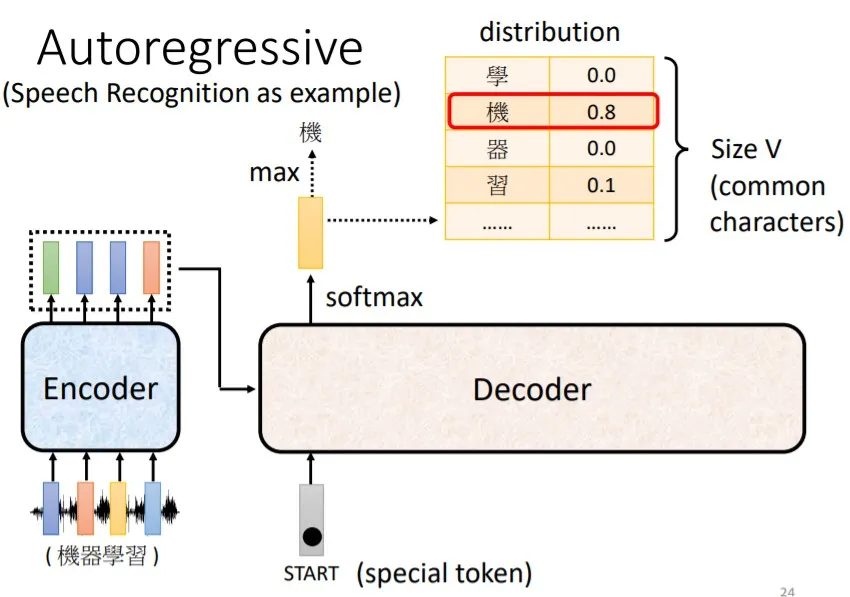
解码器输出一个向量,长度为 词表 (Vocabulary) 长度 。这个向量是一个概率分布,表示取得对应词的概率。
下图为一个自回归解码器的示意图:
项目代码主体框架梳理:
multask_frontvision |
实际调试只需要修改对应Encoder部分及模型定义即可,以RepVGG为例,具体方法为:
- 替换
Encoder对应层级的Block,将普通卷积Conv替换为RepVGGBlock;
# backbone: |
- 在
Common公共组件中添加RepVGGBlock模块类定义; - 在模型参数定义语句中添加
RepVGGBlock模块类选择。
本次关注指标主要有:
kp_detect:关键点检测。p值在0.7-0.8,r值在0.5-0.6,acc最终稳定在0.70;driver:骑行者等。acc最终稳定在0.88;occlude:遮挡。acc最终稳定在0.90。
最终效果(优化前后对比):
| FLOPs/MMac | Params/M | mean_sys/ms | std_sys/ms | mean_fps | |
|---|---|---|---|---|---|
| YOLOv8 | 116.76 | 1.88 | 5.516 | 0.176 | 181.28 |
| RepVgg(重参数化前) | 119.31 | 1.93 | 5.973 | 0.178 | 167.43 |
| RepVgg(重参数化后) | 116.63 | 1.49 | 5.197 | 0.207 | 192.42 |
| ACNet(重参数化前) | 130.9 | 2.15 | 6.261 | 0.21 | 159.73 |
| ACNet(重参数化后) | 116.5 | 1.88 | 5.237 | 0.207 | 190.93 |
| … | … | … | … | … | … |
优化前后,在计算量不变的情况下,对比发现,关键指标的检测精度基本没降(掉点约0.5%),但是推理时帧率能够稳定提升10fps,是一个相对不错的效果。
 微信
微信- 支付宝