前言 最近在做 BEVFormer_tensorrt 和 MapTR 相关代码的整合推理工作,学到了一些新的东西,对模型部署有了更深入的认识,特此记录一下。
网络结构 首先放一张论文中的示意图来进行说明,下图中,主要分为三个部分,最左边的backbone,中间×6 的encoder,中间上面的Det/Seg Heads。
第一部分就是ResNet + FPN,BEVFormer主要是在第二部分encoder进行了创新,即Temporal Self-Attention,Spatial Cross-Attention。
原文:
中文版:
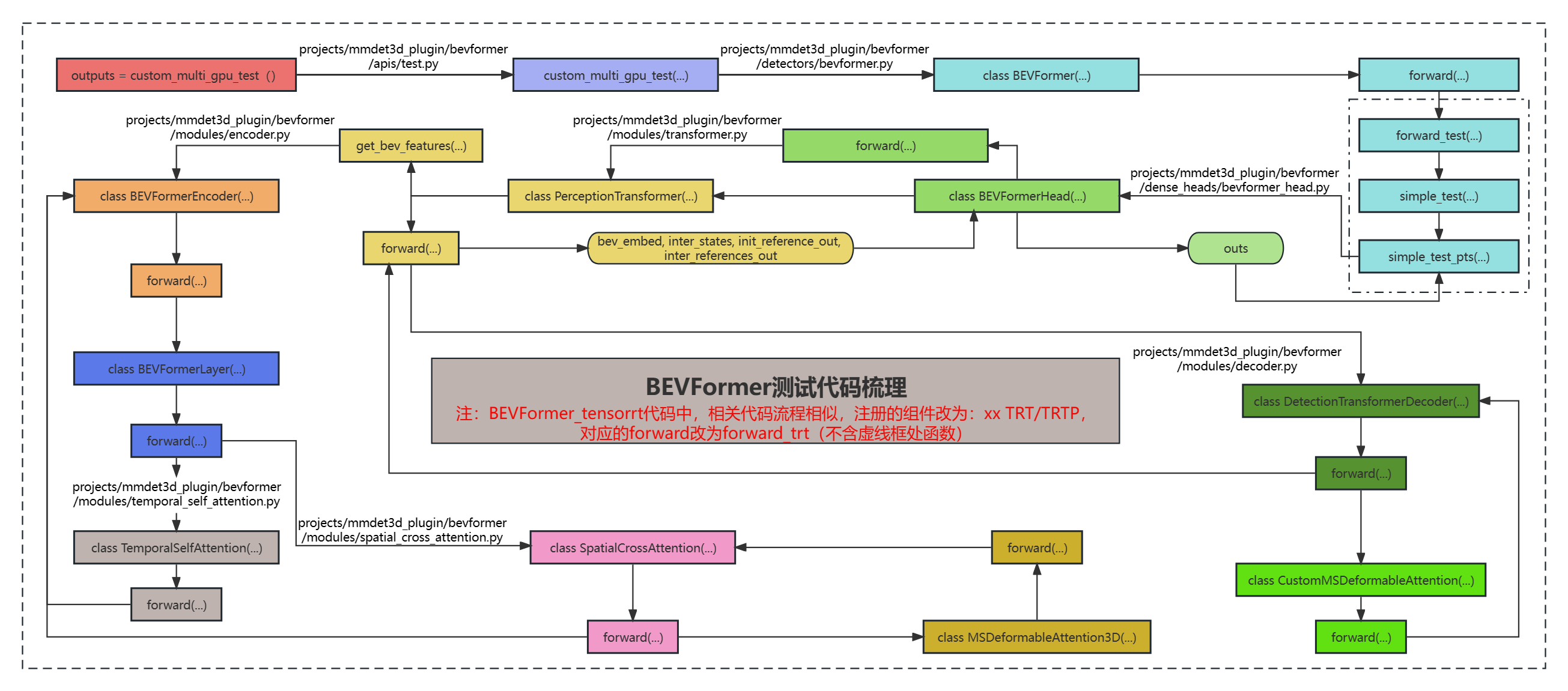
代码流程梳理图
模型配置文件 在 BEVFormer 中,几个模型之间的不同点主要在于bev_query的大小以及FPN的多尺度特征个数,我这里采用的是tiny模型进行测试,配置文件为projects/configs/bevformer/bevformer_tiny.py,模型的网络结构在此进行定义,运行时,首先会对下面的模块进行注册,从上到下基本上就是forward的步骤,下面是 BEVFormer 的model部分, BEVFormer_tensorrt 也是类似过程。
model = dick( type ='BEVFormer' , ..., img_backbone = dict ( type ='ResNet' , ... ) img_neck=dict ( type ='FPN' , ... ) pts_bbox_head = dict ( type ='BEVFormerHead' , ... transformer=dict ( type ='PerceptionTransformer' , ... encoder=dict ( type ='BEVFormerEncoder' , ... transformerlayers=dict ( type ='BEVFormerLayer' , attn_cfgs=[ dict ( type ='TemporalSelfAttention' ... ), dict ( type ='SpatialCrossAttention' , deformable_attention=dict ( type ='MSDeformableAttention3D' ... ) ) ] ) ) decoder=dict ( type ='DetectionTransformerDecoder' , ... transformerlayers=dict ( type ='DetrTransformerDecoderLayer' , attn_cfgs=[ dict ( type ='MultiheadAttention' , ...), dict ( type ='CustomMSDeformableAttention' , ...) ], ... ) ) ) bbox_coder = dict ( type ='NMSFreeCoder' ...), positional_encoding = dict ( type ='LearnedPositionalEncoding' , ...), ), ... )
自定义层的插件编写,插件库的注册 在 BEVFormer_tensorrt 项目的model中,使用到了一些自定义层,用到了一些自定义算子插件,以下对这部分插件的注册过程进行大致梳理。
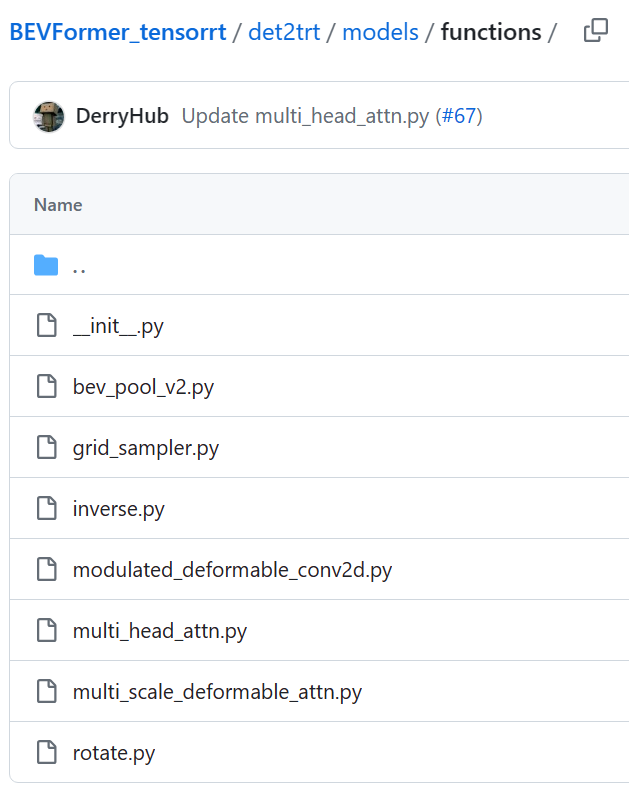
ONNX插件目录(截至8.16最新): 在./det2trt/models/utils/register.py进行模块注册定义
from mmcv.cnn.bricks.registry import CONV_LAYERSfrom mmcv.utils import Registryfrom pytorch_quantization import nn as quant_nnfrom torch import nnimport osimport ctypesclass FuncRegistry : def __init__ (self, name, build_func=None , parent=None , scope=None ): self._name = name self._module_dict = dict () ... def register_module (self, name=None , force=False , module=None ): if not isinstance (force, bool ): raise TypeError(f"force must be a boolean, but got {type (force)} " ) if not (name is None or isinstance (name, str )): raise TypeError( "name must be either of None, an instance of str or a sequence" f" of str, but got {type (name)} " ) if module is not None : self._register_module(module=module, module_name=name, force=force) return module def _register (cls ): self._register_module(module=cls, module_name=name, force=force) return cls return _register OS_PATH = "TensorRT/lib/libtensorrt_ops.so" OS_PATH = os.path.realpath(OS_PATH) ctypes.CDLL(OS_PATH) print (f"Loaded tensorrt plugins from {OS_PATH} " )CONV_LAYERS.register_module("Conv1dQ" , module=quant_nn.Conv1d) CONV_LAYERS.register_module("Conv2dQ" , module=quant_nn.Conv2d) CONV_LAYERS.register_module("Conv3dQ" , module=quant_nn.Conv3d) CONV_LAYERS.register_module("ConvQ" , module=quant_nn.Conv2d) LINEAR_LAYERS = Registry("linear layer" ) LINEAR_LAYERS.register_module("Linear" , module=nn.Linear) LINEAR_LAYERS.register_module("LinearQ" , module=quant_nn.Linear) TRT_FUNCTIONS = FuncRegistry("tensorrt functions" )
在./det2trt/models/functions/__init__.py进行初始化
from .grid_sampler import grid_sampler, grid_sampler2from .multi_scale_deformable_attn import (multi_scale_deformable_attn, multi_scale_deformable_attn2,)from .modulated_deformable_conv2d import (modulated_deformable_conv2d, modulated_deformable_conv2d2,)from .rotate import rotate, rotate2from .inverse import inversefrom .bev_pool_v2 import bev_pool_v2, bev_pool_v2_2from .multi_head_attn import qkv, qkv2from ..utils.register import TRT_FUNCTIONSTRT_FUNCTIONS.register_module(module=grid_sampler) TRT_FUNCTIONS.register_module(module=grid_sampler2) TRT_FUNCTIONS.register_module(module=multi_scale_deformable_attn) TRT_FUNCTIONS.register_module(module=multi_scale_deformable_attn2) ...
在./det2trt/models/functions/*.py进行算子定义,如rotate.py
import numpy as npimport torchfrom torch.autograd import Functionclass _Rotate (Function ): @staticmethod def symbolic (g, img, angle, center, interpolation ): return g.op("RotateTRT" , img, angle, center, interpolation_i=interpolation) @staticmethod def forward (ctx, img, angle, center, interpolation ): ... return img @staticmethod def backward (ctx, grad_output ): raise NotImplementedError def rotate (img, angle, center, interpolation="nearest" ): """ Rotate the image by angle. Support TensorRT plugin RotateTRT: FP32 and FP16(nv_half). Args: img (Tensor): image to be rotated. angle (Tensor): rotation angle value in degrees, counter-clockwise. center (Tensor): Optional center of rotation. interpolation (str): interpolation mode to calculate output values ``'bilinear'`` | ``'nearest'``. Default: ``'nearest'`` Returns: Tensor: Rotated image. """ if torch.onnx.is_in_onnx_export(): return _rotate(img, angle, center, _MODE[interpolation]) return _Rotate.forward(None , img, angle, center, _MODE[interpolation])
根据配置文件在model各模块进行调用,如:在PerceptionTransformerTRTP → get_bev_features_trt()函数中调用rotate(),由于model中设置的是1层,所以只运行了1次rotate算子,反映到ONNX模型结构中即1个RotateTRT。
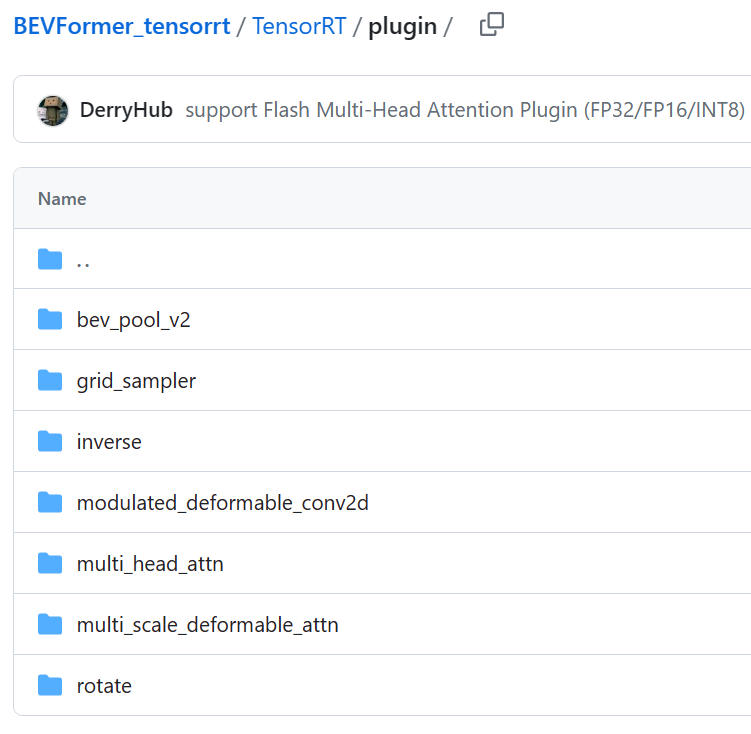
TensorRT 插件目录(截至8.16最新): TensorRT 插件(C++,编译安装)
cd ${PROJECT_DIR}/TensorRT/build cmake .. -DCMAKE_TENSORRT_PATH=/path/to/TensorRT make -j$(nproc) make install
插件编写路径(以rotate为例):
C++代码(以rotate为例):
#include "rotatePlugin.h" #include "checkMacrosPlugin.h" #include "rotateKernel.h" #include "serialize.h" #include <cuda_fp16.h> #include <stdexcept> using trt_plugin::RotatePlugin;using trt_plugin::RotatePluginCreator;using trt_plugin::RotatePluginCreator2;using namespace nvinfer1;using namespace nvinfer1::plugin;namespace {constexpr char const *R_PLUGIN_VERSION{"1" };constexpr char const *R_PLUGIN_NAME{"RotateTRT" };constexpr char const *R_PLUGIN_NAME2{"RotateTRT2" };} PluginFieldCollection RotatePluginCreator::mFC{}; std::vector<PluginField> RotatePluginCreator::mPluginAttributes; PluginFieldCollection RotatePluginCreator2::mFC{}; std::vector<PluginField> RotatePluginCreator2::mPluginAttributes; RotatePlugin::RotatePlugin (const int mode, bool use_h2) : use_h2 (use_h2) { switch (mode) { case 0 : mMode = RotateInterpolation::Bilinear; break ; case 1 : mMode = RotateInterpolation::Nearest; break ; default : break ; } } ... REGISTER_TENSORRT_PLUGIN (RotatePluginCreator);REGISTER_TENSORRT_PLUGIN (RotatePluginCreator2);
forward 流程 由于该项目涉及了很多模块,而且是用openmmlab算法体系(MMCV、MMDetection、MMDetection3D等库)实现的,有着许多相互依赖关系,且对运行环境、机器配置有着较高要求,初期复现遇到不少问题。之后通过多次调试及参考网上相关说明,我记录整理了推理的大致流程,以供后续学习参考。(路径中 “ *** ”,代表 projects/mmdet3d_plugin/bevformer )
... outputs = custom_multi_gpu_test(model, data_loader, args.tmpdir,args.gpu_collect) ...
***/apis/test.py def custom_multi_gpu_test (... ): ... for i, data in enumerate (data_loader): with torch.no_grad(): result = model(return_loss=False , rescale=True , **data) ...
class BEVFormer (...): def forward (... ): if return_loss: return self.forward_train(**kwargs) else : return self.forward_test(**kwargs) def forward_test (... ): ... new_prev_bev, bbox_results = self.simple_test(...) ... def simple_test (... ): img_feats = self.extract_feat(img=img, img_metas=img_metas) new_prev_bev, bbox_pts = self.simple_test_pts(img_feats, img_metas, prev_bev, rescale=rescale) def simple_test_pts (... ): outs = self.pts_bbox_head(x, img_metas, prev_bev=prev_bev)
class BEVFormerHead (DETRHead ): def __init__layers (... ): if not self.as_two_stage: self.bev_embedding = nn.Embedding(self.bev_h * self.bev_w, self.embed_dims) self.query_embedding = nn.Embedding(self.num_query,self.embed_dims * 2 ) def forward (... ): ''' mlvl_feats: (tuple[Tensor]) FPN网络输出的多尺度特征 prev_bev: 上一时刻的 bev_features all_cls_scores: 所有的类别得分信息 all_bbox_preds: 所有预测框信息 ''' object_query_embeds = self.query_embedding.weight.to(dtype) bev_queries = self.bev_embedding.weight.to(dtype) bev_mask = torch.zeros((bs, self.bev_h, self.bev_w), device=bev_queries.device).to(dtype) bev_pos = self.positional_encoding(bev_mask).to(dtype) if only_bev: ... else : outputs = self.transformer(...) for lvl in range (hs.shape[0 ]): outputs_class = self.cls_branches[lvl](hs[lvl]) tmp = self.reg_branches[lvl](hs[lvl]) outs = ... return out
class PerceptionTransformer (...):def forward (... ): bev_embed = self.get_bev_features(...) inter_states, inter_references = self.decoder(...) return bev_embed, inter_states, init_reference_out, inter_references_out def get_bev_features (... ): delta_x = ... grid_length_x = 0.512 grid_length_x = 0.512 shift_x = ... shift_y = ... if prev_bev is not None : ... if self.rotate_prev_bev: rotation_angle = ... can_bus = self.can_bus_mlp(can_bus)[None , :, :] bev_queries = bev_queries + can_bus * self.use_can_bus for lvl, feat in enumerate (mlvl_feats): if self.use_cams_embeds: feat = feat + self.cams_embeds[:, None , None , :].to(feat.dtype) feat = feat + self.level_embeds[None , None , lvl:lvl + 1 , :].to(feat.dtype) level_start_index = ... bev_embed = self.encoder(...) ...
***/modules/encoder.py class BEVFormerEncoder (...): def __init__ (self ): ... def get_reference_points (... ): ''' 获得参考点用于 SCA以及TSA H:bev_h W:bev_w Z:pillar的高度 num_points_in_pillar:4,在每个pillar里面采样四个点 ''' if dim == '3d' : zs = ... xs = ... ys = ... ref_3d = elif dim == '2d' : ref_2d = ... def point_sampling (... ) ''' pc_range: bev特征表征的真实的物理空间大小 img_metas: 数据集 list [(4*4)] * 6 ''' lidar2img = ... reference_points = ... reference_points_cam = torch.matmul(lidar2img.to(torch.float32), reference_points.to(torch.float32)).squeeze(-1 ) bev_mask = (reference_points_cam[..., 2 :3 ] > eps) reference_points_cam[..., 0 ] /= img_metas[0 ]['img_shape' ][0 ][1 ] reference_points_cam[..., 1 ] /= img_metas[0 ]['img_shape' ][0 ][0 ] bev_mask = (bev_mask & (reference_points_cam[..., 1 :2 ] > 0.0 ) & (reference_points_cam[..., 1 :2 ] < 1.0 ) & (reference_points_cam[..., 0 :1 ] < 1.0 ) & (reference_points_cam[..., 0 :1 ] > 0.0 )) ... @auto_fp16() def forward (... ): ''' bev_query: (2500, 1, 256) key: (6, 375, 1, 256) 6个相机图片的特征 value: 与key一致 bev_pos:(2500, 1, 256) 为每个bev特征点进行可学习的编码 spatial_shapes: 相机特征层的尺度,tiny模型只有一个,base模型有4个 level_start_index: 特征尺度的索引 prev_bev:(2500, 1, 256) 前一时刻的bev_query shift: 当前bev特征相对于上一时刻bev特征的偏移量 ''' ref_3d = self.get_reference_points(...) ref_2d = self.get_reference_points(...) reference_points_cam, bev_mask = self.point_sampling(...) shift_ref_2d += shift[:, None , None , :] if prev_bev is not None : prev_bev = torch.stack([prev_bev, bev_query], 1 ).reshape(bs*2 , len_bev, -1 ) for lid, layer in enumerate (self.layers): output = layer(...) class BEVFormerLayer (MyCustomBaseTransformerLayer ) def __init__ (... ): ''' attn_cfgs:来自总体网络配置文件的参数 ffn_cfgs:单层神经网络的参数 operation_order: 'self_attn', 'norm', 'cross_attn', 'norm', 'ffn', 'norm',encode中每个block中包含的步骤 ''' self.num_attn self.embed_dims self.ffns self.norms ... def forward (... ): ''' query:当前时刻的bev_query,(1, 2500, 256) key: 当前时刻6个相机的特征,(6, 375, 1, 256) value:当前时刻6个相机的特征,(6, 375, 1, 256) bev_pos:每个bev_query特征点 可学习的位置编码 ref_2d:前一时刻和当前时刻bev_query对应的参考点 (2, 2500, 1, 2) red_3d: 当前时刻在Z轴上的采样的参考点 (1, 4, 2500, 3) 每个特征点在z轴沙漠化采样4个点 bev_h: 50 bev_w: 50 reference_points_cam: (6, 1, 2500, 4, 2) spatial_shapes:FPN特征层大小 [15,25] level_start_index: [0] spatial_shapes对应的索引 prev_bev: 上上个时刻以及上个时刻 bev_query(2, 2500, 256) ''' for layer in self.operation_order: if layer == 'self_attn' : query = self.attentions[attn_index] elif layer == 'cross_attn' : query = self.attentions[attn_index]
***/modules/temporal_self_attention.py class TemporalSelfAttention (...): def __init__ (... ): ''' embed_dims: bev特征维度 256 num_heads: 8 头注意力 num_levels:1 多尺度特征的层数 num_points:4,每个特征点采样四个点进行计算 num_bev_queue:bev特征长度,及上一时刻以及当前时刻 ''' self.sampling_offsets = nn.Linear(...) self.attention_weights =nn.Linear(...) self.value_proj = nn.Linear(...) self.output_proj = nn.Linear(...) def forward (... ): ''' query: (1, 2500, 256) 当前时刻的bev特征图 key: (2, 2500, 256) 上一个时刻的以及上上时刻的bev特征 value: (2, 2500, 256) 上一个时刻的以及上上时刻的bev特征 query_pos: 可学习的位置编码 reference_points:每个bev特征点对应的坐标 ''' if value is None : assert self.batch_first bs, len_bev, c = query.shape value = torch.stack([query, query], 1 ).reshape(bs*2 , len_bev, c) if query_pos is not None : query = query + query_pos query = torch.cat([value[:bs], query], -1 ) value = self.value_proj(value) value = value.reshape(bs*self.num_bev_queue, num_value, self.num_heads, -1 ) sampling_offsets = self.sampling_offsets(query) sampling_offsets = sampling_offsets.view( bs, num_query, self.num_heads, self.num_bev_queue, self.num_levels, self.num_points, 2 ) attention_weights = self.attention_weights(query).view( bs, num_query, self.num_heads, self.num_bev_queue, self.num_levels * self.num_points) if reference_points.shape[-1 ] == 2 : offset_normalizer = torch.stack([spatial_shapes[..., 1 ], spatial_shapes[..., 0 ]], -1 ) sampling_locations = reference_points [][:, :, None , :, None , :] + sampling_offsets + offset_normalizer[None , None , None , :, None , :] if ...: ... else : output = multi_scale_deformable_attn_pytorch(...) output = output.view(num_query, embed_dims, bs, self.num_bev_queue) output = output.mean(-1 ) output = self.output_proj(output) return self.dropout(output) + identity def multi_scale_deformable_attn_pytorch (... ): sampling_grids = 2 * sampling_locations - 1 sampling_value_list = [] for level, (H_, W_) in enumerate (value_spatial_shapes): ... sampling_value_l_ = F.grid_sample() ... output = (torch.stack(sampling_value_list, dim=-2 ).flatten(-2 ) * attention_weights).sum (-1 ).view(bs, num_heads * embed_dims, num_queries)
***/modules/spatial_cross_attention.py class SpatialCrossAttention (...): def __init__ (... ): ''' embed_dims:编码维度 pc_range:真实世界的尺度 deformable_attention: 配置参数 num_cams:相机数量 ''' self.output_proj = nn.Linear(...) def forward (... ): ''' query:tmporal_self_attention的输出加上 self.norms reference_points:(1, 4, 2500, 3) 由 tmporal_self_attention的输出加上 模块计算的z轴上采样点的坐标,每个bev特征的有三个坐标点(x,y,z) bev_mask:(6, 1, 2500, 4) 某些特征点的值为false,可以将其过滤掉,2500为bev特征点个数,1为特征尺度,4,为在每个不同尺度的特征层上采样点的个数。 ''' for i, mask_per_img in enumerate (bev_mask): index_query_per_img = mask_per_img[0 ].sum (-1 ).nonzero().squeeze(-1 ) indexes.append(index_query_per_img) max_len = max ([len (each) for each in indexes]) queries_rebatch = query.new_zeros([bs, self.num_cams, max_len, self.embed_dims]) reference_points_rebatch = ... for j in range (bs): for i, reference_points_per_img in enumerate (reference_points_cam): ... queries = self.deformable_attention(...) class MSDeformableAttention3D (BaseModule ): def __init__ (... ): ''' embed_dims:编码维度 num_heads:注意力头数 num_levels: 4 每个z轴上的点要到每一个相机特征图上寻找两个点,所以会有8个点 ''' self.sampling_offsets = nn.Linear(...) self.attention_weights(...) self.value_proj = nn.Linear(...) def forward (... ): ''' query: (1,604,256), queries_rebatch 特征筛选过后的query query_pos:挑选的特征点的归一化坐标 ''' value = self.value_proj(value) value = value.view(bs, num_value, self.num_heads, -1 ) sampling_offsets = ... attention_weights = ... ... if torch.cuda.is_available() and value.is_cuda: ... else : output = multi_scale_deformable_attn_pytorch( value, spatial_shapes, sampling_locations, attention_weights) ... return output
***/modules/decoder.py class DetectionTransformerDecoder (...): def __init__ (... ): ... def forward (... ): ''' query: [900,1,256] bev 特征 reference_points: [1, 900, 3] 每个query 对应的 x,y,z坐标 ''' for lid, layer in enumerate (self.layers): reference_points_input = reference_points[..., :2 ].unsqueeze(2 ) output = layer(...) new_reference_points = torch.zeros_like(reference_points) new_reference_points[..., :2 ] = tmp[..., :2 ] + inverse_sigmoid(reference_points[..., :2 ]) new_reference_points[..., 2 :3 ] = tmp[..., 4 :5 ] + inverse_sigmoid(reference_points[..., 2 :3 ]) new_reference_points = new_reference_points.sigmoid() reference_points = new_reference_points.detach() ... if self.return_intermediate: intermediate.append(output) intermediate_reference_points.append(reference_points) return output, reference_points class CustomMSDeformableAttention (...): def forward (... ): ''' query: [900, 1, 256] query_pos:[900, 1, 256] 可学习的位置编码 ''' output = multi_scale_deformable_attn_pytorch(...) output = self.output_proj(output) return self.dropout(output) + identity
本机硬件配置及运行环境
CPU:16核,32G
GPU:T4平台,16G
python 3.8
TensorRT 8.5.3.1
Cuda 11.1
Torch 版本安装参考:MapTR/docs/install.md at main · hustvl/MapTR (github.com)
TensorRT 插件安装参考:DerryHub/BEVFormer_tensorrt: BEVFormer inference on TensorRT (github.com)
总结 经过上面的步骤,基本疏通了BEVFormer的推理步骤,一方面是加深对BEVFormer的理解,另一方面提高自己对BEV模型的认知。但是里面其实存在许多细节,还有一些问题之后再解决。
后记 关于ONNX,ONNX实际只是一套标准,里面只不过存储了网络的拓扑结构和权重(其实每个深度学习框架最后固化的模型都是类似的),脱离开框架是没有办法直接进行inference的。大部分框架(除了tensorflow)基本都做了ONNX模型inference的支持,这里就不进行展开了。
那么如果想直接使用ONNX模型来做部署的话,有下列几种情况:第一种情况,目标平台是CUDA或者X86的话,又怕环境配置麻烦采坑,比较推荐使用的是微软的onnxruntime ,毕竟是微软亲儿子;第二种情况,而如果目标平台是CUDA又追求极致的效率的话,可以考虑转换成TensorRT;第三种情况,如果目标平台是ARM或者其他IoT设备,那么就要考虑使用端侧推理框架了,例如NCNN、MNN和MACE等等。
第一种情况应该是坑最少的一种了,但要注意官方的onnxruntime安装包支持的CUDA和Python版本,如果是其他环境可能需要自行编译。安装完成之后推理部署的代码可以直接参考官方文档。
第二种情况要稍微麻烦一点,需要先搭建好TensorRT的环境,然后可以直接使用TensorRT对ONNX模型进行推理;然后更为推荐的做法是将ONNX模型转换为TensorRT的engine文件,这样可以获得最优的性能。关于ONNX parser部分的代码 ,NVIDIA是开源出来了的(当然也包括其他parser比如caffe的),不过这一块如果所使用的模型中包括一些比较少见的OP,可能是会存在一些坑的,比如我们的模型中包含了一个IBN结构,引入了InstanceNormalization这个OP,解决的过程可谓是一波三折;好在NVIDIA有一个论坛,有什么问题或者bug可以在上面进行反馈,专门有NVIDIA的工程师在上面解决大家的问题,不过从我两次反馈bug的响应速度来看NVIDIA还是把TensorRT开源最好,这样方便大家自己去定位bug
第三种情况的话一般问题也不大,由于是在端上执行,计算力有限,所以确保模型是经过精简和剪枝过的能够适配移动端的。几个端侧推理框架的性能到底如何并没有定论,由于大家都是手写汇编优化,以卷积为例,有的框架针对不同尺寸的卷积都各写了一种汇编实现,因此不同的模型、不同的端侧推理框架,不同的ARM芯片都有可能导致推理的性能有好有坏,这都是正常情况。


 微信
微信